Potential Duplicates Component
Explore the Potential Duplicates lightning component that surfaces possible duplicate records directly on record pages in real time. Learn how to add the component to a page layout, review and compare potential matches, merge or dismiss duplicates, and customize display fields and detection thresholds.
What You'll Learn
- Add the Potential Duplicates lightning component to any standard or custom record page
- Pick up to five matching rules per object via the gear icon configuration
- Configure cross-object matching to surface Lead/Contact duplicates
- Merge or dismiss duplicates directly from the record page without navigating away
- Understand why component results may differ from scheduled report results
Key Takeaways
- The component evaluates duplicates in real time when the record page loads
- Matching rule selection is per object, not per Lightning page
- Read-only users see duplicates but cannot merge — by design
- Limit to focused, fast matching rules to keep page load times responsive
Frequently Asked Questions
How many matching rules can the Potential Duplicates component use?
Up to 5 matching rules per object, with at most 1 cross-object matching rule. Selection is saved per object, so configuring rules for Contact applies to every Contact record page where the component is placed.
Why are the results different from the scheduled duplicate report?
The component evaluates rules in real time against the current record data, while scheduled reports may use cached results from the last scan. Different rules may also be selected in each context.
Can read-only users merge duplicates from the component?
No. Users with the No Duplicates Read Only permission set see the component and the duplicate list, but the Merge button and the gear icon are hidden. Only users with the admin permission set can merge or change rule selection.
Does the component slow down record page loading?
It can if you select many matching rules or rules that scan very large datasets. Limit to focused, fast rules — typically 2 to 3 — for good page performance, especially on high-traffic objects.
More Videos
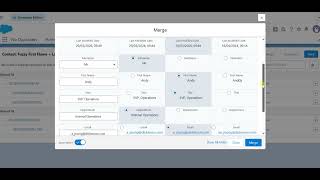
Auto-Select for Merge
Learn how Auto-Select pre-fills the merge modal with recommended field values based on your configured merge strategies. See how the modal opens ready to merge, how to review and adjust recommendations, and how Auto-Select connects to your Auto-Merge rules.
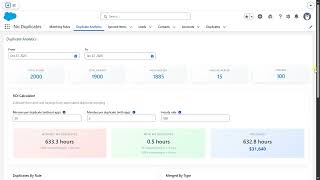
Duplicate Analytics Dashboard
Learn how to use the Duplicate Analytics dashboard to monitor duplicate trends, track merge history, and measure data quality improvements over time. This tutorial walks through navigating the dashboard, understanding trend charts, reviewing audit logs, and exporting analytics reports for stakeholders.

No Duplicates: Application Overview
Complete walkthrough of No Duplicates for Salesforce. Learn how to install and configure the app, create matching rules for Accounts, Contacts, and Leads, run duplicate scans, and review results. The video also covers setting up auto-merge strategies and scheduling recurring duplicate checks to keep your data clean automatically.